
Mastering DynamoDB: A Deep Dive into High-Performance Database Solutions
Welcome to the world of DynamoDB, Amazon’s revolutionary NoSQL database service that’s changing the game in cloud database management. At its core, DynamoDB offers a seamless blend of scalability, performance, and ease of management, making it an ideal choice for modern, data-driven applications. As we delve into DynamoDB, it’s crucial to understand what sets it apart and how it’s redefining data management in the cloud era.
Table of Contents
Introduction to DynamoDB
Deep Understanding of DynamoDB Key Concepts
- Tables
- Items
- Attributes
Exploring Primary Keys: The Backbone of DynamoDB
- Simple Primary Keys
- Composite Primary Keys
API Interactions and Operations in DynamoDB
- CRUD Operations
- Query and Scan Operations
The Strategic Role of Secondary Indexes in DynamoDB
- Types of Secondary Indexes
- Use Cases for Secondary Indexes
Advanced Data Modeling in DynamoDB
- Designing for Scale and Performance
- Handling Complex Relationships
Managing One-to-Many Relationships: Techniques and Best Practices
- Data Modeling Approaches
- Real-world Examples
Optimizing Data Access with Effective Filtering Techniques
- Designing Access Patterns
- Best Practices for Filtering
Conclusion and Future Trends in DynamoDB Usage
1. Introduction to DynamoDB
First and foremost, DynamoDB is a fully managed NoSQL database service. This means it’s not just about storing and retrieving data – it’s about doing so efficiently at a massive scale, without the overhead of server maintenance and operations. The service takes care of hardware provisioning, setup, configuration, and replication, allowing developers to focus on the application logic rather than the intricacies of database management.
One of the hallmarks of DynamoDB is its performance. It’s designed to offer single-digit millisecond response times, ensuring that even the most data-intensive applications can retrieve and manipulate data swiftly. This performance consistency is maintained regardless of the dataset size, making it a reliable choice for internet-scale applications with large user bases.
DynamoDB’s architecture is unique in its stateless operation over HTTPS. This means that interactions with the database are made over a stateless protocol, with each request being independent. This design significantly contributes to the scalability and reliability of the service. Furthermore, integration with AWS Identity and Access Management (IAM) provides robust security and fine-grained control over access to the database resources.
Another significant advantage of DynamoDB is its flexible data model. Unlike traditional relational databases that require a fixed schema, DynamoDB allows each item (record) to have any number of attributes (columns), which can vary among items. This schema-less design grants immense flexibility in data modeling, catering to the diverse needs of modern applications.
Now, let’s take a deep dive into the key concepts that form the foundation of DynamoDB.
2. Deep Understanding of DynamoDB Key Concepts
DynamoDB’s design revolves around a few fundamental concepts that are essential to grasp for effectively utilizing its full potential.
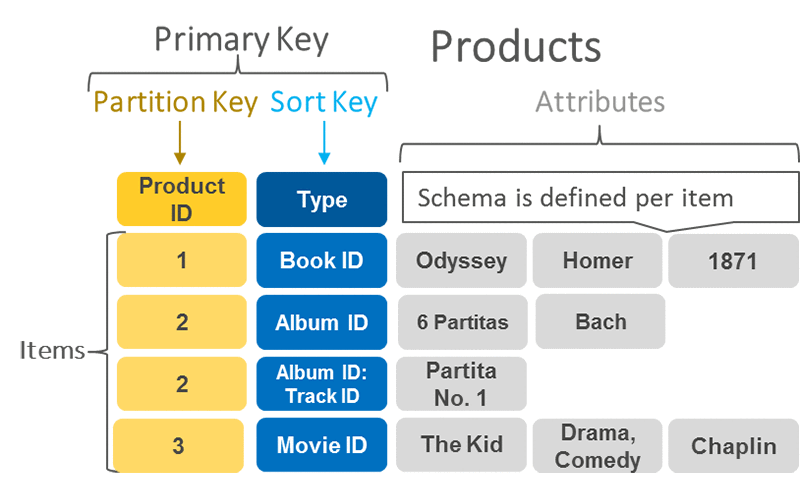
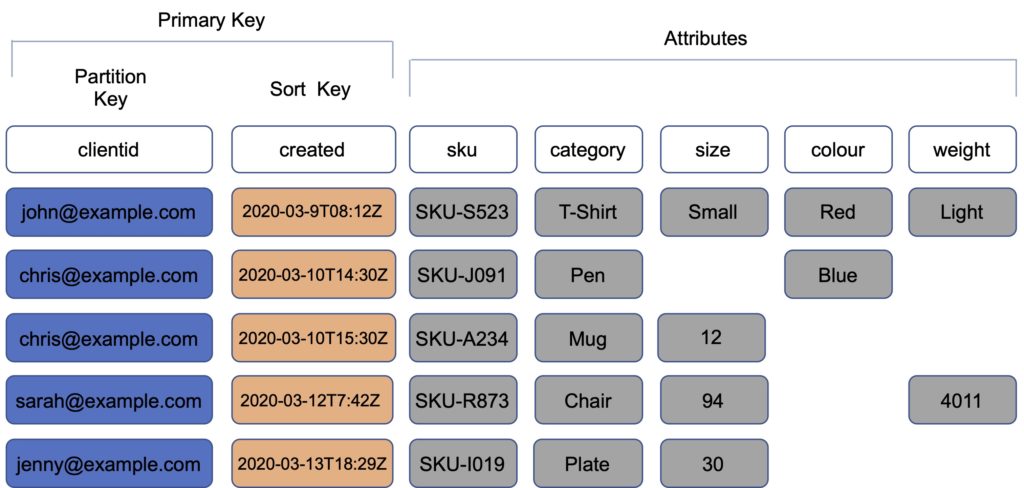
Tables: The primary data structure in DynamoDB is a table. Think of a table as a collection of data items, where each item represents a distinct entity, similar to a row in a traditional database. Tables are the top-level structure and must be defined before storing data.
Items: An item is a single data record in a DynamoDB table. Each item is identified by a primary key (discussed shortly) and can contain multiple attributes. These attributes are the data fields, and unlike in relational databases, they don’t need to be uniform across different items in the same table. This means one item can have attributes that are entirely different from another item in the same table, providing a level of flexibility that’s hard to match in traditional databases.
Attributes: An attribute in DynamoDB is a key-value pair that represents a specific data point within an item. Attributes can store various types of data, such as strings, numbers, binary data, or even lists and maps. This diversity allows DynamoDB to handle a wide range of data requirements, from simple key-value data to complex, hierarchical structures.
Understanding these concepts is the first step in leveraging DynamoDB’s power for building scalable, high-performance applications. In the following chapters, we’ll explore more advanced topics, including primary keys, secondary indexes, data modeling, and best practices for working with DynamoDB. Stay tuned as we delve deeper into the world of efficient and effective NoSQL database management with DynamoDB!
3. Exploring Primary Keys: The Backbone of DynamoDB
Primary keys are at the heart of how DynamoDB manages and retrieves data. Understanding primary keys is fundamental to effective data modeling and access in DynamoDB.
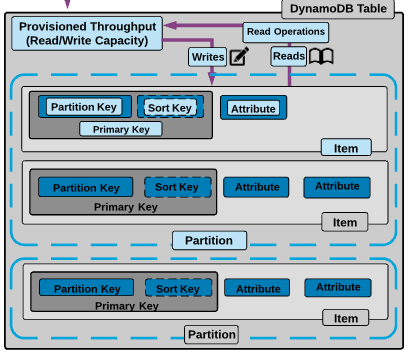
Simple Primary Keys: A simple primary key in DynamoDB is composed of a single attribute known as the ‘partition key.’ This key’s value is used by DynamoDB to determine the physical storage location of the item. The partition key’s value must be unique for each item in the table, ensuring that no two items can have the same key. This is ideal for use cases where each item can be uniquely identified by a single attribute, like a user ID, email address, or any other unique identifier.
Composite Primary Keys: More complex scenarios may require the use of a composite primary key, which includes two attributes: a partition key and a sort key. The partition key functions similarly to the simple primary key, determining the item’s storage. The sort key adds an additional level of data sorting within each partition. This arrangement allows for storing multiple items with the same partition key but differentiated by the sort key. It’s particularly useful for hierarchical data structures, like threaded discussions, where the partition key might be a thread ID, and the sort key could be a timestamp or a reply ID.
4. API Interactions and Operations in DynamoDB
DynamoDB’s operations and interactions are primarily API-driven, making it highly flexible and integrable with various application architectures.
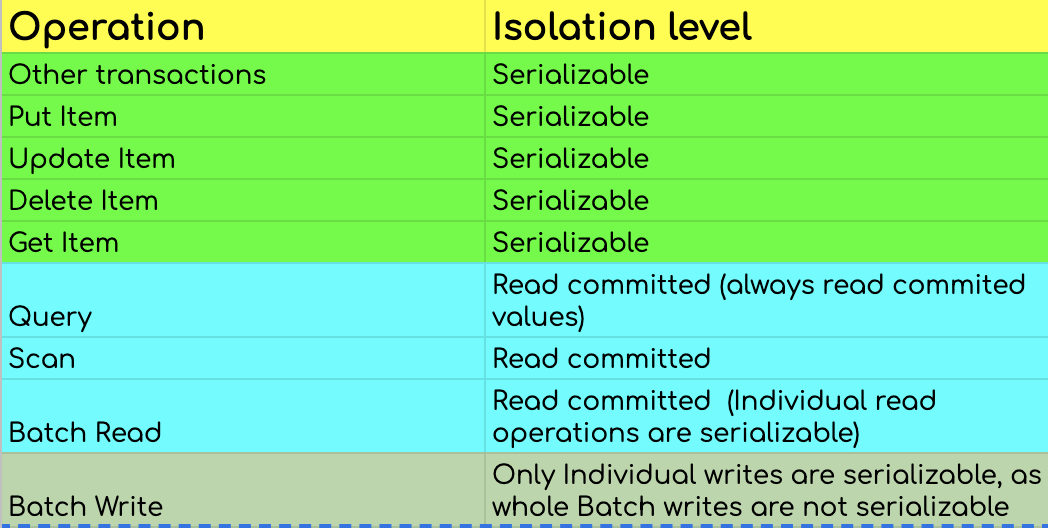
CRUD Operations: The core of DynamoDB’s functionality lies in its CRUD (Create, Read, Update, Delete) operations. These operations are fundamental for interacting with data stored in DynamoDB.
- Create: Adding new items to a table. This involves specifying the primary key and any additional attributes.
- Read: Retrieving items from a table. This can be done either by querying for specific primary key values or scanning for items that match certain criteria.
- Update: Modifying existing items in a table. DynamoDB allows for updating one or more attributes of an item without affecting others.
- Delete: Removing items from a table. This is typically done by specifying the primary key of the item to be deleted.
Query and Scan Operations: Beyond basic CRUD, DynamoDB offers two powerful operations for retrieving data: queries and scans.
- Query Operations: Querying in DynamoDB is efficient and allows for retrieving items based on primary key values. You can specify conditions for the sort key (if using a composite primary key) and use filters to refine the results further. Queries are ideal for situations where you know the partition key and, optionally, the sort key.
- Scan Operations: Scan operations examine every item in a table or a secondary index. While powerful, scans can be resource-intensive and potentially slower, especially for large tables. Scans are best used for situations where you need to retrieve all items that match certain criteria, regardless of their primary key values.
Understanding and mastering these primary keys and API operations are crucial for any developer or database administrator working with DynamoDB. They form the basis of data management and retrieval in this robust NoSQL service, enabling the design of efficient, scalable, and high-performance applications.
5. The Strategic Role of Secondary Indexes in DynamoDB
In DynamoDB, secondary indexes are pivotal for enhancing the database’s querying capabilities. They play a strategic role in facilitating flexible data access patterns that are not possible through primary keys alone.
Types of Secondary Indexes:
- Local Secondary Indexes (LSI): An LSI is tied to the same partition key as the primary key but has a different sort key. This allows for more diverse querying options within the same partition. However, one limitation of LSIs is that they must be created at the same time as the table and cannot be modified or added later.
- Global Secondary Indexes (GSI): GSIs are more versatile. They can have a different partition key and sort key than those of the primary key. This flexibility allows GSIs to span across all the data in a table, regardless of partitions. They can be created and modified after the table is created, offering greater flexibility in evolving data models.
Use Cases for Secondary Indexes: Secondary indexes are crucial for scenarios where access patterns require querying on attributes that are not part of the primary key. For example, if you have a user database with a primary key of UserID, but you often need to retrieve users based on their email address, a GSI with the email address as a partition key would be highly beneficial. This expands query capabilities significantly, enabling efficient data retrieval based on various business needs and user behaviors.
6. Advanced Data Modeling in DynamoDB
Data modeling in DynamoDB involves a strategic approach to designing tables and choosing keys, keeping in mind the scalability and performance requirements.
Designing for Scale and Performance:
- Choosing the Right Key Schema: Selecting appropriate primary keys (and secondary indexes) is crucial. The key schema should align with the most common access patterns to ensure efficient data retrieval.
- Anticipating Access Patterns: Understanding how the application will access the data is essential. This involves thinking about the queries that will be run against the database and ensuring that the data model supports these queries efficiently.
- Avoiding Hotspots: Even distribution of data across partitions is vital to avoid overloading a single partition, known as a hotspot. This involves careful selection of partition keys to ensure that data and request loads are evenly distributed.
Handling Complex Relationships:
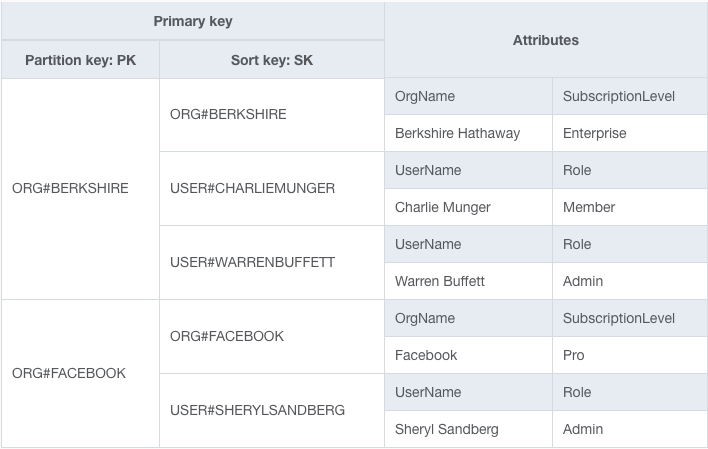
- One-to-Many Relationships: These can be handled by using a composite primary key (partition key and sort key) where the partition key represents the “one” side, and the sort key represents the “many” side.
- Many-to-Many Relationships: This is more complex and often requires using additional tables or GSIs to efficiently model the relationships.
- Hierarchical Data: Can be modeled using composite primary keys, where the hierarchy is represented through the sort key in various ways, depending on the specific use case.
Advanced data modeling in DynamoDB is about understanding the nuances of how data is accessed and stored. It requires a balance between the flexibility of a NoSQL database and the efficiency of a well-structured data model. By carefully planning and implementing a data model that aligns with your application’s access patterns, you can harness the full power of DynamoDB’s scalability and performance capabilities.
7. Managing One-to-Many Relationships: Techniques and Best Practices
One-to-many relationships are common in database design, and DynamoDB offers several techniques to manage them efficiently.
Data Modeling Approaches:
- Single-Item Aggregations: In some cases, it’s feasible to aggregate multiple related entities into a single item. This approach is efficient for read-heavy use cases where the related entities are frequently accessed together.
- Composite Primary Keys: Utilizing composite primary keys (partition key and sort key) is a common strategy. The partition key represents the ‘one’ side of the relationship, and the sort key represents the ‘many’ side. This setup allows for efficient querying of all related items.
Real-world Examples:
- Blogging Platform: In a blog application, posts and comments can be modeled in a single table. The post ID serves as the partition key, and comments are differentiated using the sort key (e.g., timestamp or comment ID).
- Order Management System: Orders and order items can be modeled with the order ID as the partition key. Order items can use the order ID as their partition key and a unique identifier as the sort key.
8. Optimizing Data Access with Effective Filtering Techniques
Effective data access in DynamoDB often hinges on the design of data retrieval patterns and the efficient use of filtering capabilities.
Designing Access Patterns:
- Understand Query Patterns: Design your table structure based on how your application queries the data. Anticipate common queries and optimize the data model accordingly.
- Use Secondary Indexes: Secondary indexes can be used to support additional access patterns not covered by the primary key.
Best Practices for Filtering:
- Filtering at the Source: Whenever possible, use key conditions to filter data at the source rather than retrieving large datasets and filtering them application-side.
- Efficient Use of Filter Expressions: While filter expressions are powerful, they are applied only after the data is read. Hence, they should be used judiciously to avoid unnecessary read operations.
9. Conclusion and Future Trends in DynamoDB Usage
As we’ve seen, DynamoDB’s flexible and scalable nature makes it a formidable choice for modern, data-driven applications. Its ability to handle large-scale workloads with ease and its integration with the broader AWS ecosystem make it an attractive option for businesses looking to leverage cloud computing.
Future Trends:
- Increased Adoption in Serverless Architectures: DynamoDB’s seamless integration with AWS Lambda and other serverless services will likely drive its increased adoption in serverless computing models.
- Enhancements in Global Data Management: As businesses become more global, features like DynamoDB Global Tables will become more critical for managing data across different geographical regions.
- Evolution in Data Modeling Practices: As developers and architects gain more experience with DynamoDB, we can expect to see the evolution of more sophisticated data modeling practices that maximize its performance and scalability benefits.
In summary, DynamoDB’s evolution will likely continue in step with the advancements in cloud computing, offering more robust features, enhanced performance, and seamless scalability for a wide range of applications.
FAQs About DynamoDB
Q: What makes DynamoDB stand out in the realm of NoSQL databases? A: Its seamless scalability, high availability, and low latency performance make DynamoDB a standout choice for large-scale applications.
Q: How does DynamoDB’s flexible schema benefit data modeling? A: The flexibility allows for varying attribute sets across items, enabling dynamic adaptation to evolving data requirements without the need for schema migrations.
Q: Can DynamoDB integrate with other AWS services for enhanced functionality? A: Absolutely! DynamoDB integrates well with AWS Lambda for serverless computing, Amazon Redshift for data warehousing, and many other AWS services, enhancing its utility and versatility in complex architectures.
Q: What is DynamoDB and why is it used? A: DynamoDB is a fully managed NoSQL database service provided by Amazon Web Services (AWS). It is used for its scalability, high performance, and flexibility in managing data for applications with large-scale, low-latency requirements.
Q: How does DynamoDB differ from traditional relational databases? A: Unlike traditional relational databases, DynamoDB is schema-less, supports NoSQL data models, and is designed for high scalability and performance. It allows each item to have a varying number of attributes and uses primary keys for data retrieval.
Q: What are primary keys in DynamoDB, and why are they important? A: Primary keys in DynamoDB uniquely identify each item in a table and are crucial for data retrieval. There are two types: simple primary keys (partition key only) and composite primary keys (partition key plus sort key).
Q: Can you explain the concept of secondary indexes in DynamoDB? A: Secondary indexes in DynamoDB provide additional query capabilities beyond the primary key. There are two types: Local Secondary Indexes (LSI) and Global Secondary Indexes (GSI). LSIs have the same partition key as the primary key but a different sort key, whereas GSIs can have different partition and sort keys.
Q: What are some common data modeling strategies in DynamoDB? A: Common data modeling strategies include using single-table designs where multiple entity types are stored in one table, and designing primary keys and secondary indexes to align with application’s access patterns.
Q: How are one-to-many relationships handled in DynamoDB? A: One-to-many relationships in DynamoDB can be managed using composite primary keys, where the partition key represents the ‘one’ side and the sort key represents the ‘many’ side. This allows for efficient querying and data organization.
Q: What are some best practices for querying and scanning in DynamoDB? A: Best practices include using queries instead of scans whenever possible, as queries are more efficient. When using scans, apply filters to reduce the amount of data processed. Also, consider using secondary indexes to support additional query patterns.
Q: How does DynamoDB handle large-scale and high-performance requirements? A: DynamoDB handles large-scale and high-performance requirements through its distributed architecture, which automatically scales to accommodate high throughput. Its design allows for consistent, single-digit millisecond latency for data access.
Q: Can DynamoDB be integrated with other AWS services? A: Yes, DynamoDB integrates well with various AWS services, such as AWS Lambda for serverless applications, Amazon Redshift for data warehousing, and AWS Data Pipeline for data movement and transformation.
Q: What are some future trends in DynamoDB usage? A: Future trends include increased adoption in serverless architectures, enhancements in global data management with features like DynamoDB Global Tables, and the evolution of more sophisticated data modeling practices to leverage its full potential.
Q: Is DynamoDB suitable for all types of applications? A: While DynamoDB is highly versatile, it is particularly suited for applications requiring fast access to large volumes of data, such as web-scale applications. It may not be the best fit for applications with complex transactional needs or those requiring extensive relational data modeling.
Q: How does DynamoDB ensure data security? A: DynamoDB ensures data security through integration with AWS Identity and Access Management (IAM), which allows for fine-grained access control to the database resources, and supports encryption at rest and in transit for data security.