
Rodolfo Guluarte Hale
Full-Stack Engineer
Usando Modelo Vicuna en Google Colab
Vicuna fue el primer modelo de código abierto disponible públicamente que es comparable con la salida de GPT-4. Se afinó en el modelo LLaMA 13B de Meta y el conjunto de datos de conversaciones recopilado de ShareGPT. ShareGPT es el sitio web donde la gente comparte sus conversaciones de ChatGPT con otros.
¿Cómo funciona el modelo Vicuna?
Los investigadores extrajeron aproximadamente 70.000 conversaciones del sitio web ShareGPT. El siguiente paso es introducir mejoras sobre el modelo original Alpaca. Para manejar mejor las conversaciones de varias rondas, ajustaron la pérdida de entrenamiento. También aumentaron la longitud máxima del contexto de 512 a 2048 para comprender mejor las secuencias largas.
Luego evaluaron la calidad del modelo creando un conjunto de 80 preguntas diversas de 8 categorías diferentes (codificación, matemáticas, escenarios de rol, etc.). El siguiente paso es recopilar respuestas de cinco chatbots: LLaMA, Alpaca, ChatGPT, Bard y Vicuna y luego pidieron a GPT-4 que calificara la calidad de sus respuestas en función de la utilidad, la relevancia, la precisión y el detalle. En resumen, se utilizó la API de GPT-4 para evaluar el rendimiento del modelo.
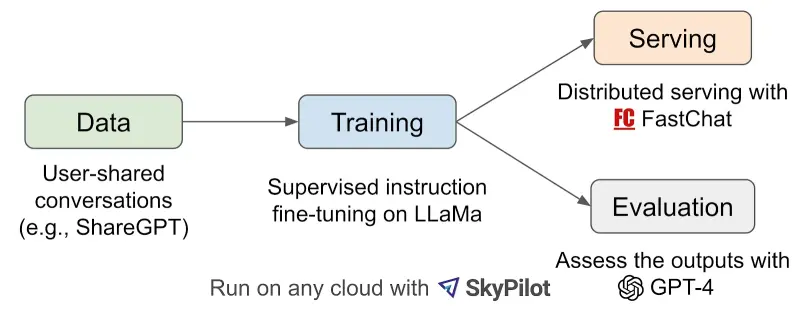
Rendimiento del modelo
Los investigadores afirmaron que Vicuna alcanzó el 90% de capacidad de ChatGPT. Esto significa que es aproximadamente tan bueno como GPT-4 en la mayoría de los escenarios. Como se muestra en la imagen a continuación, si GPT-4 se considera como un punto de referencia con una puntuación base de 100, el modelo Vicuna obtuvo 92, que está cerca de la puntuación de Bard de 93.
Demo
El equipo también desarrolló una interfaz web del modelo para fines de demostración https://chat.lmsys.org/.
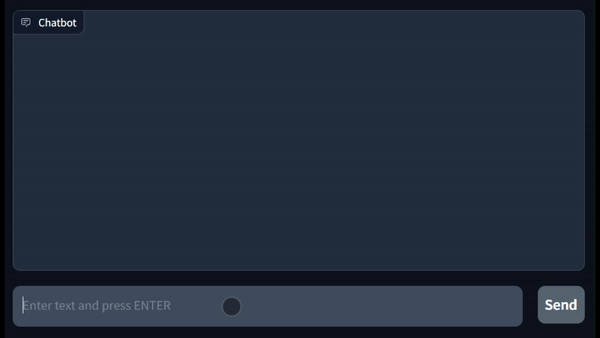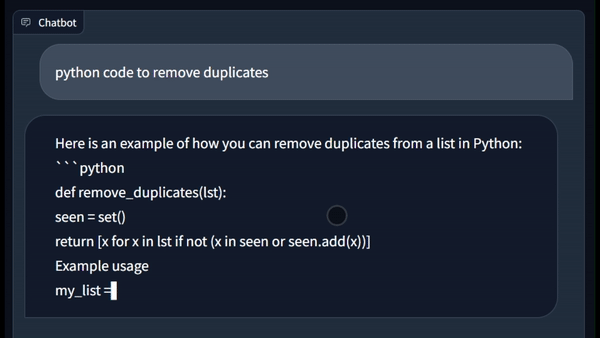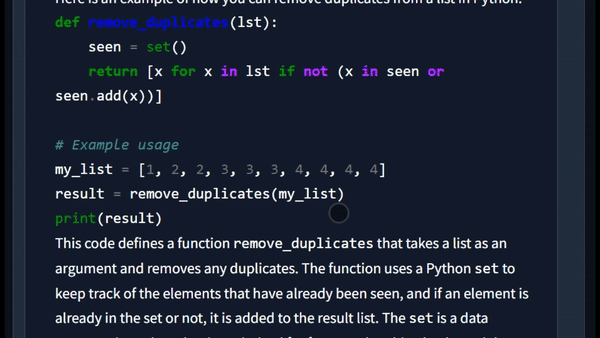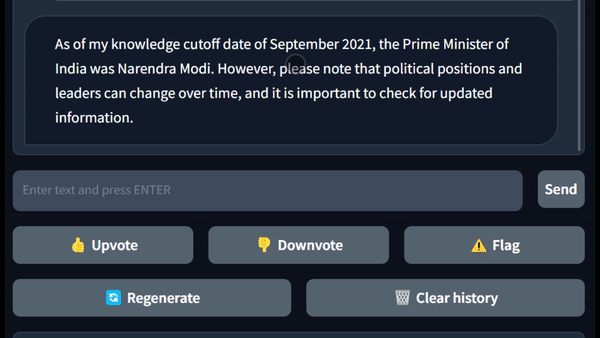
Requisitos de memoria
Requiere una sola GPU con al menos 12 GB de VRAM.
Código Python
He creado un cuaderno de colab como guía paso a paso para ejecutar el modelo.
Paso 1: Instalar Text Generation WebUI
Text Generation WebUI es una interfaz web desarrollada en Gradio para facilitar la ejecución de modelos de lenguaje grandes.
!git clone https://github.com/oobabooga/text-generation-webui
%cd text-generation-webui
!pip install -r requirements.txt
Paso 2: configuración del modo de soporte de 4 bits
La cuantización es una técnica que se utiliza para reducir los requisitos de memoria y computación del modelo de aprendizaje automático al representar los pesos y las activaciones con menos bits. En los modelos de lenguaje grandes, la cuantización de 4 bits también se utiliza para reducir los requisitos de memoria del modelo para que pueda ejecutarse con menos RAM. Algunas investigaciones también demostraron que la cuantización de 4 bits también mantiene una alta precisión.
En el código a continuación, estamos creando una carpeta de repositorios que almacena los repositorios GPTQ-for-LLAMA (cuantización de 4 bits de LLaMA usando GPTQ).
%mkdir /content/text-generation-webui/repositories/
%cd /content/text-generation-webui/repositories/
!git clone https://github.com/oobabooga/GPTQ-for-LLaMa.git -b cuda
%cd GPTQ-for-LLaMa
!pip install ninja
!pip install -r requirements.txt
!python setup_cuda.py install
Paso 3: Descargar el modelo
En este paso estamos descargando la versión cuantizada de 4 bits del modelo vicuna-13b. Es importante descargar el archivo .pt o .safetensors del modelo.
%cd /content/text-generation-webui/
!python download-model.py --text-only anon8231489123/vicuna-13b-GPTQ-4bit-128g
!wget https://huggingface.co/anon8231489123/vicuna-13b-GPTQ-4bit-128g/resolve/main/vicuna-13b-4bit-128g.safetensors
Mueve el archivo .pt o .safetensors
Asegúrate de que el archivo .pt o .safetensors esté guardado en la carpeta de modelos.
!mv /content/text-generation-webui/anon8231489123_vicuna-13b-4bit-128g.safetensors /content/text-generation-webui/models/anon8231489123_vicuna-13b-GPTQ-4bit-128g/anon8231489123_vicuna-13b-4bit-128g.safetensors
!pip install --ignore-installed Pillow==9.3.0
Paso final: Ejecutar la aplicación web.
!python server.py --share --model anon8231489123_vicuna-13b-GPTQ-4bit-128g --model_type llama --chat --wbits 4 --groupsize 128